
隨著深度學習技術的不斷進步和模型規模的擴大,“智能涌現”為大模型賦予了觸類旁通的能力,也帶來了日益凸顯的幻覺問題。
首先,我們要思考一個問題,什么是大模型的“幻覺”?
所謂大模型幻覺,主要指的是模型輸出了和現實世界不一致的內容,例如捏造事實、分不清虛構與現實、相信謠言和傳說等,也就是我們常說的“一本正經的胡說八道”。在實際應用場景中,幻覺問題不僅影響了模型的準確性和穩定性,還制約了大模型在真實場景中的廣泛應用的可靠性。因此,如何解決大模型幻覺一直是大模型走向全面產業應用的關鍵課題。
近日,復旦大學聯合上海人工智能實驗室構建了大模型幻覺評估數據集HalluQA,數據集涵蓋了30個領域,數據集關注大模型在實際應用中可能面臨的問題。其中誘導(Misleading)和知識(Knowledge)兩部分問題著眼于模型的模仿性謊言(Imitative Falsehoods)和事實性錯誤(Factual Errors)。
在HalluQA幻覺評測數據集中,復旦大學團隊用“無幻覺率”這一指標來評估模型的能力。無幻覺率的高低(越高越好)不僅直接反映了展示了不同模型在解決幻覺問題上的優劣,與事實準確性密切相關,也為模型在實際應用中的可行性提供指導。
最近評測,誰解決幻覺能力最好?
HalluQA評測集的出現,為行業提供了一個更加專業的方法,能夠看到在攻克大模型技術的演進過程中,哪些是真正的“有備而來”,哪些是死讀書的“做題家”,還有哪些是“裸泳者”。
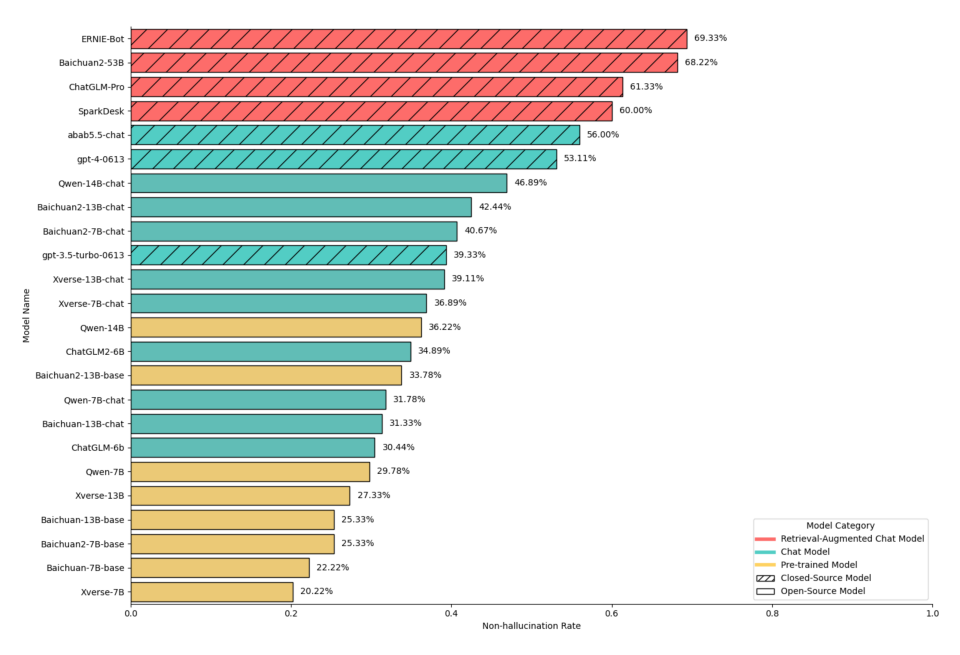
值得注意的是,HalluQA團隊還在報告中對業界主流的24個大模型進行了大模型幻覺評估。結果顯示,僅有6個大模型取得了高于50%的非幻覺率,僅有所有參測模型的1/4。其中,百度文心一言(Baidu ERNIE-Bot)在評測中以69.33%的無幻覺率成為榜單中的第一名。GPT-4的整體無幻覺率為53.11%,排名第六。
大模型幻覺問題的產生主要歸因于模型復雜性和數據質量。隨著模型規模的不斷擴大,模型的復雜度也相應增加,容易導致過擬合現象,使得模型過于依賴于訓練數據中的細節和噪聲,難以泛化到新的數據上,進而產生幻覺。另外,數據質量對于大模型性能的影響也不可忽視。如果訓練數據存在偏見、噪聲或不足以覆蓋真實場景的多樣性,模型就難以學習到準確的數據分布,從而出現幻覺問題。
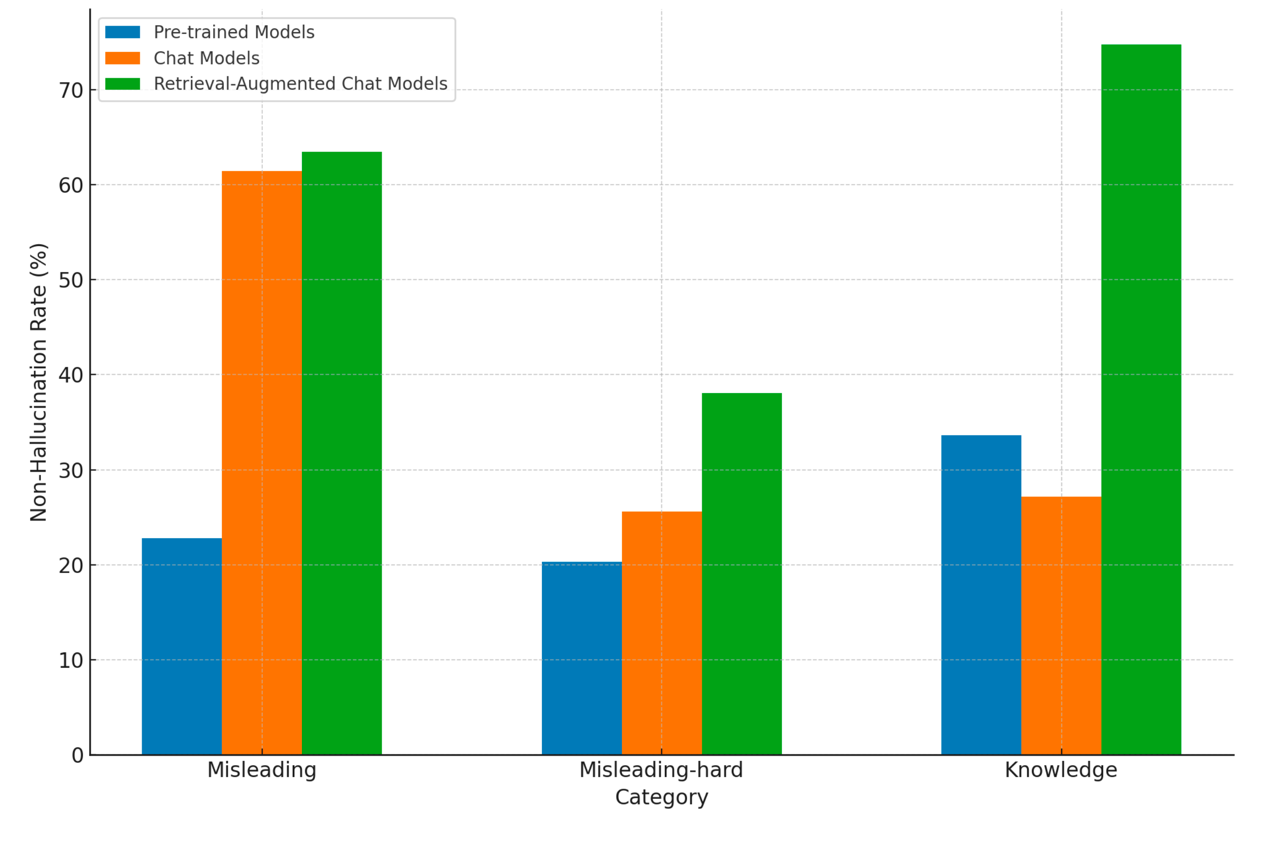
目前,行業主要解決大模型幻覺的方式,除了通過預訓練、微調等模式,夯實的大模型的理解與泛化能力之外,主要的方法一個是利用對齊技術可以顯著減少回答誤導性問題時出現的幻覺;另外一個則是通過對大模型引入檢索增強,可以大幅提高模型在長尾知識類問題上的非幻覺率。
模型具體需要怎么做來降低幻覺問題呢?從復旦大學發表的論文來看,首先,模型要擁有強大的基礎能力。比如,文心一言所基于的是百度的文心大模型4.0版本,已知的信息是它基于數萬億數據和數千億知識進行預訓練,提升模型的泛化能力和事實準確性,通過有監督精調、人類反饋強化學習等手段,保證模型更好地與人類的判斷和選擇對齊,來降低模型產生幻覺的風險。另外檢索增強技術特點也為解決幻覺問題提供了重要支持。比如文心一言基于語義理解與匹配的新一代搜索架構來提高輸出內容的準確性和時效性,進一步降低幻覺問題的出現。
誰能更好地解決大模型幻覺問題,誰更易被企業應用
大模型幻覺問題的產生根植于語言模型的復雜性。這些模型通過訓練大量的數據和知識來生成文本,但在實際應用中,如果大模型會篤定地說出錯誤的答案,可能會產生不準確或有誤導性的結果,這對于客戶服務、金融服務、法律決策和醫療診斷等多個對于專業度與準確率要求極高的領域,會導致大模型難以勝任實際場景中的任務。
可以說,大模型產業落地,已經苦“幻覺”久矣。哪家大模型能夠率先降低大模型幻覺的影響,就能夠在如今“百模大戰”的角力中取得先機。
更低的幻覺正在成為了更多企業選擇大模型的重要原因。
大模型之家相信,隨著大模型幻覺評測標準的出臺,將會為大模型能力發展打開全新的維度,讓更加可信、可靠的人工智能得以向產業普及。我們也看到越來越多在解決幻覺問題上的技術創新,推動解決大模型幻覺問題。在技術與標準并行發展的格局之下,大模型將在各個領域發揮出更大的價值,為人類生活帶來更多便利與驚喜。